|
יחידה 10: רגרסיה וניבוי לינארי >> 10.2: אומדן ברמת האוכלוסייה |
|||||
|
אומדן ברמת האוכלוסייה
עד כה דיברנו על ניבוי ברמת המדגם, אך אנו נרצה להשתמש בנתוני המדגם ולחשב אומדן על נתונים שלא היו כלולים במדגם המקורי.
תחילה נחשב את האומדן הבלתי מוטה של (שונות הטעויות):
כאשר המתאם שווה לאפס סה"כ שונות y היא בערך שונות הטעויות כאשר המתאם שווה לאחד שונות הטעויות שואפת לאפס. |
|||||
|
באוכלוסייה:
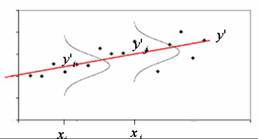
עבור כל ערך קיימת התפלגות של ערכי y. הממוצע שלהם הוא y’ וסטיית התקן
במטרה לנבא את y, אנו לא נסתפק באומדן נקודתי, אלא נעדיף לנבא טווח של ערכים, ברמת בטחון נתונה – זהו בעצם רווח בר סמך. לצורך כך אנו צריכים את אומדן הטעויות .
טעות נוספת שעלינו לקחת בחשבון נובעת מכך שחישוב קו ניבוי המבוסס על r (אשר חושב מתוך מדגם מקרי) שהוא אומדן ל- . בכל מדגם שניקח אנו עשויים לקבל מתאם קצת שונה. מכיוון שכל הקווים עוברים דרך מפגש הממוצעים הטעות שנובעת מבחירת הקו משפיעה יותר על ערכים שרחוקים מממוצע x. ככל ש-x, כלומר המשתנה המנבא, רחוק יותר מממוצע x, כך הסיכוי לטעות גדול יותר.יש לזכור שהאומדן של ממוצע x וממוצע y גם הם מקורם במדגם אך השפעת אומדן זה קטנה יותר.
|
|||||
|
אנו נשתמש בנוסחת רווח בר סמך שתיקח בחשבון הן את הטעות שמסביב לקו והן את הטעות שנובעת מבחירת הקו עצמו.
להזכירכם, נוסחת הרב"ס: . הפרמטר שאנו מבקשים לבנות עבורו רווח בר סמך הוא רמת
הכולסטרול של אנשים במשקל לכך מוסיפים כפול סטיית התקן של הטעויות - טעות התקן.
בהתחשב בשני סוגי הטעויות גם יחד (הטעות מסביב לקו ובחירת הקו עצמו), ברמת בטחון של הערך המנובא y באמצעות x שווה ל: . |
|||||
|
שני גורמי ההשפעה נמצאים בתוך השורש המוכפל בשונות הטעויות:
השפעת ה-n: ככל שהמדגם גדול יותר, כך סביר שהסטטיסטי r מתקרב יותר לפרמטר , ולכן הטעות הנובעת מבחירת הקו קטנה יותר – לכן n נמצא במכנה.
מרחק x מהממוצע שלו: ריבוע מרחק x מהממוצע של x לחלק ב- : . ככל ש-x מרוחק מממוצע ה-x-ים אנו עושים טעות גדולה יותר בבחירת הקו זאת משום שהקווים הולכים ומתפצלים. |
|||||
|
דוגמא:
|
|||||
|
|
|||||
|
פתרון:
מחשבים את הממוצעים, סטיות התקן, המתאם ואז את קו הניבוי:
עכשיו ניתן לחשב את הציון המנובא ל-22 בחלק הסגור לפי קו הניבוי במדגם:
עתה נחשב את האומדן לשונות הטעויות:
עכשיו יש למצוא את לפי ה- EXCEL , , או לפי הטבלה, ואז להציב את יתר הערכים שבשורש.
קיבלנו ש: , טווח ערכים הגדול יחסית הנובע מן ה-n הקטן שבמדגם. |
|||||
|
חישוב ציון t בתוך הרווח בר-סמך
מה הסיכוי של אביב לקבל לפחות 51 במבחן? הממוצע בחלק הסגור עבור מי שקיבל 22 בחלק הפתוח הוא . אם בחלק הפתוח אביב קיבל 22, הוא צריך ציון של לפחות 29 בחלק הסגור (כדי שציון המבחן שלו יהיה לפחות 51).
בעצם מדובר בהתפלגות של ציונים בחלק הסגור, ואנו מעוניינים לחשב ציון t ל-29. במכנה מופיע:
לא נהוג, למרות שנכון, לעשות תיקון לרציפות. - חישוב זה ניתן לעשות רק באמצעות EXCEL. כלומר שהסיכוי לקבל מעל 29 בהתפלגות t עם 8 דרגות חופש הוא 24%. סיכויו של אביב לקבל לפחות 51 במבחן הוא 24%. |
|||||
|